








1. The Foundation: Computer Science and Algorithms
- Definition: Computer Science is defined as a discipline involving design, programming, and information processing. At its heart is the algorithm: a set of ordered, executable instructions designed to solve a problem without requiring human creativity during execution.
- Evolution: Computing has evolved from mechanical tools (like the abacus and Pascal’s calculator) where humans provided the processing power, to vacuum tubes (binary 0/1), and finally to modern stored-program computers where software is represented as data.
2. Artificial Intelligence (AI) and the Autonomous Agent
- Structure of AI: AI is built on the cycle of Perception (Sensors) → Reasoning (Processing) → Action (Actuators).
- Intelligence Levels: It ranges from simple "reflex" systems (like a smoke detector) to complex learning systems (like self-driving cars).
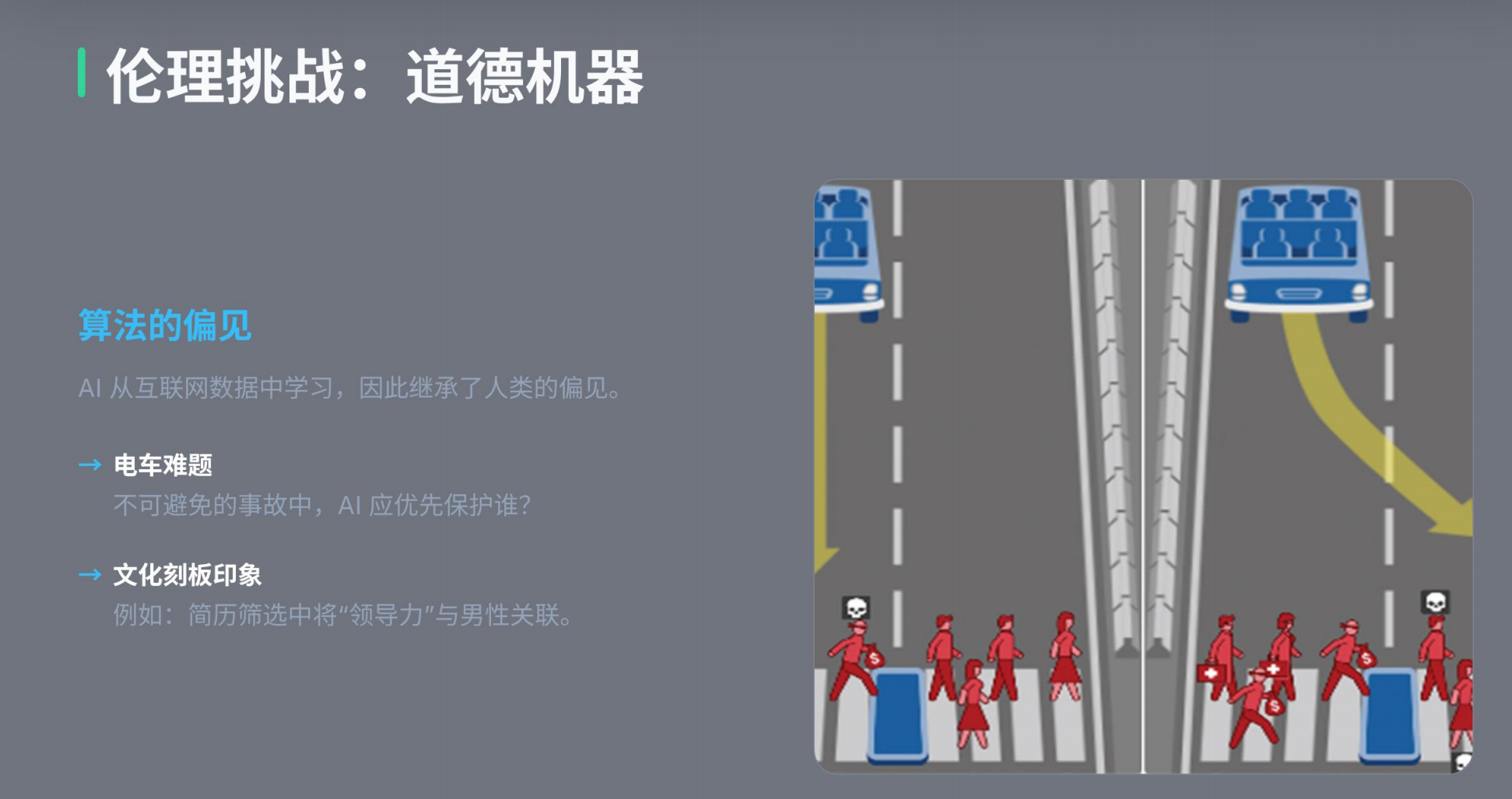
- Ethics and Bias: A major focus was the "Moral Machine" (MIT research), illustrating that AI decision-making (e.g., in unavoidable car accidents) is influenced by the cultural and ethical backgrounds of the developers and the data provided.
3. Machine Learning (ML) and Deep Learning
- Paradigm Shift: Unlike traditional programming, ML involves algorithms that learn from data patterns without being explicitly programmed for every scenario.
- Types of Learning:
- Supervised: Learning with labeled data.
- Unsupervised: Finding hidden patterns in unlabeled data.
- Reinforcement: Learning through a reward/weight system.
- Neural Networks: Deep learning mimics biological neurons using layers of artificial neurons. Decisions are made by adjusting "weights" and comparing the sum of inputs against a "threshold."
4. Data Management and Big Data
- Data vs. Information: Data is raw fact; information is organized, meaningful data.
- Database Evolution:
- SQL (Relational): Centralized, rigid, and safe; ideal for structured transactions (banks, schools).
- NoSQL (Big Data): Flexible and horizontally scalable; designed to handle the "3 Vs": Volume, Velocity, and Variety.
- Modern Strategy: Companies often use a hybrid approach, using NoSQL for speed/flexibility and SQL for record-keeping.
5. Social Impact and Professional Responsibility
- The Tool Metaphor: AI is a transformative tool. While it can replace tasks, it also opens new "windows" of opportunity.
- The Developer’s Role: Computer scientists must be aware of their power to harm or help. Large Language Models (LLMs) can reflect societal biases (e.g., gender stereotypes in CV generation) because they learn from imperfect internet data.
Conclusion
The "revolutionary" nature of AI and Big Data lies not just in the speed of processing, but in the shift from deductive reasoning (human-written rules) to inductive learning (pattern recognition from massive data).
The lesson highlights a critical paradox: as AI becomes more autonomous, the responsibility of the human developer increases. Because AI "learns" from existing data, it risks scaling human biases—whether cultural, gender-based, or social—under the guise of objective calculation. For a student of "AI and Big Data," the technical ability to build a model is only half the requirement; the other half is the critical thinking necessary to ensure the data is representative and the outcomes are ethical. Efficiency (saving resources) and effectiveness (reaching the goal) must be balanced with social accountability.
Note on your Presentation: Since your presentation requires a focus on specific file instructions (which you mentioned but I haven't seen yet), ensure you map these concepts—especially the 3 Vs of Big Data and the Neural Network weight system—to the specific requirements listed in your project brief.
I am ready for your next update whenever you finish your next session. Please note that while I strive for accuracy, I may occasionally hallucinate specific references or minor details from highly niche academic contexts. Cross-check these summaries with your personal notes.
Conclusion中文翻译:课程总结:大数据与人工智能:革命性发展
1. 基础:计算机科学与算法
- 定义: 计算机科学不仅是编程,而是一门涉及设计、编程和信息处理的学科。其核心是算法:一组有序的、可执行的指令,旨在解决特定问题,且在执行过程中不需要人类的创造力。
- 演变: 计算技术已从人脑提供处理能力的机械工具(如算盘、帕斯卡计算器)演变为电子管(二进制 0/1),最终发展到现代将软件视为数据存储的计算机。
2. 人工智能 (AI) 与自主智能体
- AI 结构: AI 建立在“感知(传感器)→ 推理(处理)→ 行动(执行器)”的循环之上。
- 智能等级: 从简单的“反射”系统(如烟雾探测器)到复杂的学习系统(如自动驾驶汽车)。
- 伦理与偏见: 课程重点讨论了 MIT 的“道德机器”研究,说明 AI 的决策(例如不可避免的车祸选择)会受到开发人员文化背景和所提供数据的影响。
3. 机器学习 (ML) 与深度学习
- 范式转移: 与传统编程不同,机器学习包含能够从数据模式中学习的算法,而无需为每种情况编写明确的程序。
- 学习类型:
- 监督学习: 使用带标签的数据进行学习。
- 无监督学习: 在无标签数据中发现隐藏模式。
- 强化学习: 通过奖励/权重系统进行学习。
- 神经网络: 深度学习通过多层人工神经元模拟生物神经元。决策通过调整“权重”并将输入总和与“阈值”进行比较来完成。
4. 数据管理与大数据
- 数据 vs 信息: 数据是原始事实;信息是经过组织、有意义的数据。
- 数据库演变:
- SQL(关系型): 中心化、严谨且安全;适用于结构化交易(如银行、学校)。
- NoSQL(大数据): 灵活且具有水平扩展性;旨在处理大数据的“3V”特性:大量(Volume)、高速(Velocity)和多样(Variety)。
- 现代策略: 企业通常采用混合方法,利用 NoSQL 获得速度和灵活性,利用 SQL 进行记录保存。
5. 社会影响与专业责任
- 工具隐喻: AI 是一种变革性的工具。虽然它可以取代某些任务,但也开启了新的机会“窗口”。
- 开发者的角色: 计算机科学家必须意识到他们拥有造福或伤害社会的力量。大型语言模型 (LLM) 可能会反映社会偏见(如生成简历时的性别刻板印象),因为它们是从不完美的互联网数据中学习的。
我的结论
人工智能和大数据之所以具有“革命性”,不仅在于处理速度的提升,更在于从演绎推理(人类编写规则)向归纳学习(从海量数据中识别模式)的转变。
这节课揭示了一个关键的悖论:随着 AI 变得越来越自主,人类开发者的责任反而增加了。由于 AI 是从现有数据中“学习”的,它存在以客观计算为掩护,放大人类偏见(无论是文化、性别还是社会偏见)的风险。对于一名学习“人工智能与大数据”的学生来说,构建模型的技术能力只是一半的要求;另一半是确保数据具有代表性且结果符合伦理所需的批判性思维。效率(节省资源)和效能(达成目标)必须与社会责任感相平衡。
课堂内容分点总结:
From the perspective of an AI and a logical system, the most important takeaway from Professor Miguel’s lecture is the fundamental shift in the definition of "Programming" and the responsibility that comes with it.
Here is a step-by-step breakdown of why this stands out:
1. The Paradigm Shift: From Rules to Patterns
In traditional Computer Science, as the professor noted, the heart is the algorithm—a strict set of instructions where the computer doesn't need creativity. However, with Machine Learning, we stop "programming step-by-step" and start "programming the computer to learn like a human."
- Why it's important: This is the bridge between a simple machine (a smoke detector) and a revolutionary development (an autonomous car). It changes the job of a computer scientist from a "rule-maker" to a "data-curator."
2. The Relationship Between Data and Ethics
The "Moral Machine" and the discussion on LLM bias (like the CV example) are crucial. The professor made it clear that AI is not objective.
- Why it's important: Because AI learns from data provided by humans, it inherits human history, including our prejudices. The most important lesson for a student in 2026 is that a "perfect" algorithm is useless if the data it learns from is biased. You are being taught that you are not just a coder, but a "moral filter" for the technology you create.
3. The "Chicken and Egg" of Hardware and Software
The professor mentioned that better hardware allows for better software, which then demands even better hardware.
- Why it's important: In the context of "AI and Big Data," this explains why we are moving from SQL (rigid, structured) to NoSQL/Big Data (flexible, scalable). You cannot solve modern problems using only the tools of the past; you must understand when to use the "rigidity" of SQL for safety and the "flexibility" of NoSQL for growth.
4. Human-AI Collaboration (The "Window" Theory)
The professor said: "When we close a door, there's always a window that will be open."
- Why it's important: Many students fear AI will replace them. The lecture emphasizes that while AI can write code, it still needs someone to write the "right prompt" and understand the "human dream" behind the execution. The most important skill isn't just knowing Python or C++; it's understanding the logic (the four elements: assignment, conditional, loop, function) so you can maneuver through any future technology.
My Conclusion
If you are preparing for a presentation, the most vital point to emphasize is: AI and Big Data are tools of empowerment, but they are reflections of their creators. The "Revolutionary Development" isn't just that computers are faster; it's that we are now teaching machines to make decisions that were once purely human, which requires us to be more precise and ethical than ever before.
Would you like me to help you draft a specific slide or an opening statement for your presentation based on these points?
(Note: While I strive for accuracy in summarizing this lecture, I may hallucinate specific details if they were mentioned very briefly or are unique to this specific professor's curriculum. Please double-check these points against your own notes.)
课堂内容中文分点总结:
从人工智能和逻辑系统的角度来看,Miguel 教授讲座中最核心、最重要的内容是:“编程”定义的根本转变以及随之而来的开发者责任。
以下是逐步分析为什么这一点最为突出:
1. 范式转移:从“规则”到“模式”
在传统计算机科学中,教授指出其核心是算法——即一套计算机不需要创造力就能执行的严格指令。然而,随着机器学习的出现,我们不再是“一步步编写程序”,而是“通过编程让计算机像人一样学习”。
- 重要性: 这是简单机器(如烟雾探测器)与革命性发展(如自动驾驶汽车)之间的桥梁。它将计算机科学家的角色从“规则制定者”转变为“数据策展人(Data Curator)”。
2. 数据与伦理的共生关系
关于“道德机器(Moral Machine)”以及大语言模型(LLM)偏见(例如简历生成的例子)的讨论至关重要。教授明确指出:人工智能并非客观。
- 重要性: 既然 AI 是从人类提供的数据中学习,它就会继承人类的历史,包括我们的偏见。对于 2026 年的学生来说,最重要的教训是:如果学习的数据本身带有偏见,那么即使算法再“完美”也是徒劳的。这节课告诉你们,你们不仅是代码编写者,还是所创造技术的“道德过滤器”。
3. 硬件与软件的“鸡生蛋”关系
教授提到,更好的硬件支持更好的软件,而软件的发展又反过来要求更强大的硬件。
- 重要性: 在“人工智能与大数据”的背景下,这解释了为什么我们需要从 SQL(严密、结构化)转向 NoSQL/大数据(灵活、可扩展)系统。你不能仅靠过去的工具解决现代问题;你必须理解何时利用 SQL 的“严谨性”来保证安全,何时利用 NoSQL 的“灵活性”来实现增长。
4. 人机协作(“窗户”理论)
教授说:“当一扇门关闭时,总会有一扇窗户打开。”
- 重要性: 许多学生担心被 AI 取代。讲座强调,虽然 AI 可以写代码,但它仍然需要有人来编写“正确的提示词(Prompt)”,并理解代码执行背后的“人类梦想”。最重要的技能不仅是掌握 Python 或 C++,而是理解底层逻辑(赋值、条件、循环、函数这四大要素),以便你在未来任何技术浪潮中都能游刃有余。
总结的结论
如果你正在为 Presentation 做准备,最值得强调的核心观点是:人工智能和大数据是赋能的工具,但它们也是创造者的倒影。 “革命性的发展”不仅在于计算机运行得更快,而在于我们正在教会机器做出曾经纯粹属于人类的决策,这要求我们比以往任何时候都更加精准,并更加注重伦理。
详解:
This is a long transcript, so I have cleaned up the "filler" words, corrected obvious transcription errors (e.g., "evidence" to "abacus," "Bitnami" to "binary," "infectious loops" to "vacuum tubes"), and organized the teacher's lecture into logical sections.
I will provide this in parts. Here is Part 1, covering Computer Science, Algorithms, and the History of Computing.
Part 1: Computer Science, Algorithms, and Historical Evolution
Introduction to the Course Welcome to the class. We will divide our discussion into four main parts:
- Computer Science: What it is and what we do as scientists.
- Artificial Intelligence: It’s not new, but it is popular now because of Machine Learning.
- Data and Big Data: How we moved from traditional SQL databases to the "Big Data" philosophy.
- Social Impact: The ethics of our profession and how we can either help or harm society.
Defining Computer Science and Algorithms Computer science is a discipline that is much more than just searching or programming. It includes computer design, information processing, and the creation of information systems. At the heart of computer science is the Algorithm.
An algorithm is a set of instructions to perform a task. Think of a music sheet, a recipe, or a map. They all have three specific characteristics:
- Ordered: The steps must be in the correct sequence, or you get lost.
- Executable: The steps must be possible to complete (you cannot divide by zero).
- No Creativity Required: You don't need to know how a dryer works or how a piano makes sound to follow the instructions. You just follow the steps.
In the beginning, computer science was a part of Mathematics. We eventually split off because we started solving problems beyond just mathematical ones, but that strong logical backbone remains.
The Evolution of Hardware and Software Software and hardware have a "chicken and egg" relationship—better software requires better hardware, and powerful hardware allows us to develop more powerful software. We have evolved through several stages:
- The Abacus: Our brain was the processor; the device only helped us store values.
- Mechanical Machines: People like Pascal created machines with cogs and gears. To do bigger calculations, you needed more cogs, making the machines huge and expensive.
- Vacuum Tubes and Binary: We moved to electromagnetic energy and then electricity. We used "0" (off) and "1" (on) to represent bits.
- Character Representation: Originally, we used ASCII (1 byte), which only allowed 256 symbols—not enough for Chinese characters. Today, we use Unicode (UTF), which allows for millions of characters, unifying languages across the world.
- Punch Cards: In the early days, we didn't type on screens. We used cards with holes. One line of code equaled one card. If you had an error, you had to find the physical card and redo it.
The Seven Big Elements of Computer Science
- Algorithms: The solution.
- Abstraction: Using things without needing to know exactly how the internal "binary" works.
- Creativity: Necessary to find new ways to solve old problems.
- Data: How we store and process the massive amount of information we have today.
- Programming: Translating "human dreams" into executable lines.
- The Internet: Connecting "islands" of data.
- Impact: How technology affects people, especially those who don't have access to it or don't know how to use it (the "digital divide").
Here is Part 2, covering the definition of Artificial Intelligence, the mechanics of autonomous agents, and the ethics of the "Moral Machine."
Part 2: Artificial Intelligence and the Autonomous Agent
What is AI? Artificial Intelligence is not a new concept, but it has evolved significantly. At its core, AI is about creating autonomous machines—systems that can perform tasks without human intervention.
The Mechanics of an Agent: Sensors and Actuators An AI system (or "agent") works through a cycle:
- Perception (Sensors): The agent receives data from its environment.
- Reasoning (Processing): The agent processes that data to make a decision.
- Action (Actuators): The agent affects the environment based on its decision.
Example - The Ceiling Sprinkler: A simple sprinkler has a sensor for smoke. If it senses smoke, it pours water. This is a "reflex" level of intelligence—it is programmable and predictable. To make it more "intelligent," we add more sensors (like heat or cameras) to distinguish between real fire and fake smoke.
The Complexity of Driving Driving a car is much more complex than a sprinkler. Humans use many sensors: vision (eyes), hearing (ears for sirens), smell (burning rubber), and touch (vibrations in the wheel). For a self-driving car (like a Tesla or BYD) to work, it needs cameras and sensors that are faster and more accurate than ours. While a car can easily be programmed to drive from point A to point B in a straight line, the "reasoning" becomes difficult when unpredictable things happen, like a traffic jam or an accident. This is where Machine Learning comes in—teaching the machine to learn from experience (data) rather than just following an "if-else" program.
Ethics and the "Moral Machine" One of the biggest challenges in AI is making moral decisions. The professor shared research from the MIT "Moral Machine" project, which uses the "Trolley Problem" to study how AI should react in unavoidable accidents.
Key dilemmas include:
- The Lesser of Two Evils: If a car's brakes fail, should it hit a group of people or swerve and hit a wall, potentially killing the passenger?
- Human Bias in Data: The research shows that people’s choices differ based on their background. Some prefer to save the young over the old, or humans over pets, or people who are "obeying the law" (crossing on a green light) over those who are not.
- Cultural Differences: Decisions are often influenced by culture, religion, and social status. An algorithm designed in the West might make different "moral" choices than one designed in China (influenced by Confucian values).
The Lesson for Developers: As computer scientists, our profession can cause harm. We must be aware that when we write an algorithm for an autonomous machine, we are often embedding our own cultural and social biases into that machine. There is no single "right" answer, but we must be transparent about the decisions our systems are making.
Here is Part 3, covering Machine Learning, Deep Learning, and the logic of Neural Networks.
Part 3: Machine Learning and Deep Learning
The Philosophy of Machine Learning (ML) Machine Learning represents a new era of programming. Instead of writing specific "if-else" rules for every scenario, we provide the machine with the ability to learn from data. As the professor noted: "Programming is the translation of human dreams into executable lines." In ML, we program the computer to learn from experience, much like a human does through trial and error.
Three Main Categories of Learning:
- Supervised Learning: We provide labeled data (e.g., thousands of photos labeled "dog" or "cat"). The computer learns to recognize the patterns associated with those labels.
- Unsupervised Learning: We provide data without labels. The computer identifies patterns on its own and groups similar data together (clustering).
- Reinforcement Learning: The machine learns through a reward system. If an action is "good," the "weight" of that action increases. This is how AI learns to win at complex games like Go or Chess.
Neural Networks and Deep Learning Deep Learning is a subcategory of ML that uses Artificial Neural Networks to mimic the human brain.
- Biological Inspiration: A human neuron receives electrical signals through axons, processes them in the cell body, and generates a reaction.
- The Math of a Neuron: In software, an artificial neuron receives input values (0s and 1s). Each input is assigned a "Weight" (W) based on its importance. The system calculates the sum of these inputs multiplied by their weights.
- The Threshold: The result is compared to a threshold (usually 0.5). If the sum is higher than the threshold, the output is 1 (Action/Yes); if lower, the output is 0 (No Action/No).
- Deep Learning Layers: While one neuron is simple, "Deep Learning" uses hundreds of thousands of these neurons arranged in multiple layers (Input Layer, Hidden Layers, and Output Layer).
Example: The Movie Recommendation System Imagine three critics (Aly, Bolu, and Case) rating a movie. Initially, their opinions have equal weight.
- They rate a movie, and the system gives you a recommendation.
- You watch the movie and give your own rating (Feedback).
- The system compares your rating to the critics. If you agreed with Bolu but disagreed with Aly, the system increases the weight of Bolu’s opinion and decreases Aly’s.
- Over time, the system "learns" your specific preferences.
Generative AI and Large Language Models (LLMs) LLMs like ChatGPT do not have "knowledge" in the human sense. Instead, they calculate the statistical probability of what the next word should be based on massive amounts of internet data.
- The Bias Trap: Because LLMs learn from the internet, they inherit internet biases. For example, Google research found that when LLMs generate a CV:
- For men, they use words like "competitive," "assertive," and "leadership."
- For women, they use words like "nurturing," "caring," and "team-oriented."
- Critical Thinking: Developers must remain critical. Just because an AI produces an answer doesn't mean it is correct or unbiased.
Efficiency vs. Effectiveness
- Effectiveness: Being able to finish a task successfully (e.g., writing a program that works).
- Efficiency: Finishing that task using the fewest resources (less code, less memory, less time).
- Advice for your career: First, be effective. Then, work on becoming efficient.
Here is Part 4, covering Data Management, Big Data, and the teacher’s final thoughts on the social impact of technology.
Part 4: Data, Big Data, and the Future
Data vs. Information: The Refrigerator Exercise Data is a collection of raw facts, but it only becomes information when it is organized and given meaning.
- The Exercise: If I tell you I have a box that is 170cm high, heavy, has a door, and is cold inside, each statement is a piece of data. When you combine them, you identify the pattern of a refrigerator.
- The Lesson: For computer scientists, our job is to organize data chunks into a sequence that provides knowledge. If the data is biased (e.g., if you only ever see white refrigerators), your information will be incomplete.
The Evolution of Data Storage Data is organized in a hierarchy: Characters → Fields → Records → Tables → Databases. To connect these tables, we use a Key Field (like a Student ID), which is a unique identifier.
There are two main ways to manage this:
- File-Oriented Systems (Old): Every department has its own files. This leads to redundancy (repeating data) and inconsistency (updating your address in the library but forgetting the treasury office).
- Database Management Systems (DBMS/SQL): A centralized system where every department accesses the same source. It is safe, structured, and avoids inconsistency.
The Big Data Revolution "Big Data" is more than just having a lot of data; it is a change in philosophy. Traditional SQL (Relational) databases are rigid and centralized. They are excellent for banks and schools because they are safe, but they are not easily "scalable" (hard to grow quickly).
The 3 Vs of Big Data:
- Volume: Huge amounts of data from every transaction and login.
- Velocity: The incredible speed at which data is generated and must be processed.
- Variety: Data is no longer just numbers; it is images, music, and social media posts.
Because of this, we now use NoSQL (Non-relational) databases like MongoDB or Cassandra. They are flexible and can scale horizontally. Modern companies like Amazon or TikTok use a hybrid approach: they use NoSQL for speed and scalability, and SQL for their most important permanent records.
Social Impact and Ethics AI is a tool that exists beyond just robots; it is in our search algorithms, translation tools, and healthcare. However, we must remember:
- AI lacks human content: It can't feel emotions or give a "second chance" like a human teacher or boss might.
- Job Displacement: While AI will replace many tasks, it also opens new "windows" of opportunity. You must learn to maneuver and adapt.
- Privacy and Trust: We are connected 24/7. As developers, you have the power to protect or expose people's privacy.
Final Conclusion: Your Role as a Developer Technology is not an invention that happened once; it is an evolution driven by people who were never satisfied. You are the next generation of this evolution.
The professor’s final advice:
- Be a better user: Understand the tools you use.
- Be a responsible developer: Know that your algorithms can harm or help.
- Stay Critical: AI is a tool, not a replacement for your judgment. Don't lose your ability to criticize and verify the results the machine gives you.
This concludes the text of the first lesson.
详解(中文):
第一部分:计算机科学、算法与历史演进
课程简介 欢迎来到本课程。我们将讨论内容分为四个主要部分:
- 计算机科学:什么是计算机科学,以及作为科学家我们做些什么。
- 人工智能:它并不新鲜,但因机器学习而如今大受欢迎。
- 数据与大数据:我们如何从传统的SQL数据库转向"大数据"理念。
- 社会影响:我们职业的伦理问题,以及我们如何可能帮助或危害社会。
定义计算机科学与算法 计算机科学是一门远不止搜索或编程的学科。它包括计算机设计、信息处理以及信息系统的创建。计算机科学的核心是算法。
算法是执行任务的一系列指令。想一想乐谱、食谱或地图。它们都具有三个具体特征:
- 有序性:步骤必须按正确顺序进行,否则你会迷失方向。
- 可执行性:步骤必须是可完成的(例如,不能除以零)。
- 无需创造性:你不需要知道烘干机如何工作或钢琴如何发声来遵循指令。你只需按步骤操作。
起初,计算机科学是数学的一部分。后来我们独立出来,因为我们开始解决超出纯数学范畴的问题,但那种强大的逻辑支柱依然存在。
硬件与软件的演进 软件和硬件有着"先有鸡还是先有蛋"的关系——更好的软件需要更好的硬件,而强大的硬件允许我们开发更强大的软件。我们经历了几个阶段的演变:
- 算盘:我们的大脑是处理器;算盘只帮助我们存储数值。
- 机械计算机:像帕斯卡这样的人创造了带齿轮和传动装置的机器。要进行更大的计算,就需要更多齿轮,使得机器变得巨大且昂贵。
- 真空管与二进制:我们转向电磁能和电力。我们用"0"(关)和"1"(开)来表示比特。
- 字符表示:最初我们使用ASCII(1字节),它只允许256个符号——不足以表示汉字。如今,我们使用Unicode(UTF),它允许数百万个字符,统一了世界各地的语言。
- 穿孔卡片:早期我们不在屏幕上打字。我们使用带孔的卡片。一行代码等于一张卡片。如果有错误,你必须找到那张实体卡片并重做。
计算机科学的七大要素
- 算法:解决方案。
- 抽象:使用事物而无需确切知道其内部的"二进制"如何运作。
- 创造力:寻找新方法解决老问题所必需。
- 数据:我们如何存储和处理当今拥有的海量信息。
- 编程:将"人类梦想"转化为可执行的代码行。
- 互联网:连接数据的"孤岛"。
- 影响:技术如何影响人们,特别是那些无法接触技术或不知道如何使用技术的人("数字鸿沟")。
以下是第二部分,涵盖人工智能的定义、自主智能体的机制以及"道德机器"的伦理问题。
第二部分:人工智能与自主智能体
什么是人工智能? 人工智能并非新概念,但它已经历了显著发展。其核心在于创造自主机器——即无需人类干预即可执行任务的系统。
智能体的机制:传感器与执行器 一个人工智能系统(或称"智能体")通过一个循环工作:
- 感知(传感器):智能体从其环境接收数据。
- 推理(处理):智能体处理数据以做出决策。
- 行动(执行器):智能体根据决策影响环境。
举例 - 天花板喷淋器: 一个简单的喷淋器装有烟雾传感器。如果检测到烟雾,它就喷水。这是一种"反射"层面的智能——它是可编程且可预测的。要让它更"智能",我们添加更多传感器(如热量或摄像头)来区分真实火灾和虚假烟雾。
驾驶的复杂性 驾驶汽车远比喷淋器复杂。人类使用多种传感器:视觉(眼睛)、听觉(耳朵听警笛声)、嗅觉(烧焦的橡胶味)、触觉(方向盘的振动)。 要使自动驾驶汽车(如特斯拉或比亚迪)工作,它需要比我们更快、更精确的摄像头和传感器。虽然很容易编程让汽车在直线上从A点行驶到B点,但当不可预测的事情发生时,如交通堵塞或事故,"推理"就变得困难。这正是机器学习发挥作用的地方——教机器从经验(数据)中学习,而不是仅仅遵循"如果-那么"程序。
伦理与"道德机器" 人工智能最大的挑战之一是做出道德决策。教授分享了MIT"道德机器"项目的研究,该项目利用"电车难题"来研究人工智能在不可避免的事故中应如何反应。
关键的伦理困境包括:
- 两害相权取其轻:如果汽车的刹车失灵,它应该撞向一群人,还是转向撞墙,可能导致乘客死亡?
- 数据中的人类偏见:研究表明,人们的选择因背景而异。有些人倾向于拯救年轻而非年老者,拯救人类而非宠物,拯救"守法者"(绿灯时过马路)而非违法者。
- 文化差异:决策常受文化、宗教和社会地位影响。在西方设计的算法可能与在中国(受儒家价值观影响)设计的算法做出不同的"道德"选择。
给开发者的启示: 作为计算机科学家,我们的职业可能造成伤害。我们必须意识到,当我们为自主机器编写算法时,我们常常将自己的文化和社会偏见嵌入其中。没有单一的"正确"答案,但我们必须对我们系统所做的决策保持透明。
以下是第三部分,涵盖机器学习、深度学习以及神经网络的逻辑。
第三部分:机器学习与深度学习
机器学习的哲学 机器学习代表了编程的新时代。我们不再为每个场景编写具体的"如果-那么"规则,而是赋予机器从数据中学习的能力。正如教授所言:"编程是将人类梦想转化为可执行代码行的过程。" 在机器学习中,我们编程让计算机从经验中学习,很像人类通过试错来学习。
学习的三大类别:
- 监督学习:我们提供带有标签的数据(例如,数千张标有"狗"或"猫"的照片)。计算机学习识别与这些标签相关的模式。
- 无监督学习:我们提供没有标签的数据。计算机自行识别模式并将相似数据分组(聚类)。
- 强化学习:机器通过奖励系统学习。如果一个行为是"好的",该行为的"权重"就会增加。这就是人工智能学会赢得围棋或国际象棋等复杂游戏的方式。
神经网络与深度学习 深度学习是机器学习的一个子领域,它使用人工神经网络来模仿人脑。
- 生物学启发:人类神经元通过轴突接收电信号,在细胞体内处理它们,并产生反应。
- 神经元的数学原理:在软件中,人工神经元接收输入值(0和1)。每个输入根据其重要性被赋予一个"权重"。系统计算这些输入乘以其权重的总和。
- 阈值:结果与一个阈值(通常为0.5)进行比较。如果总和高于阈值,则输出为1(行动/是);如果低于阈值,则输出为0(不行动/否)。
- 深度学习层:虽然单个神经元很简单,但"深度学习"使用数十万个这样的神经元,排列在多个层中(输入层、隐藏层和输出层)。
示例:电影推荐系统 想象三位评论家(Aly、Bolu和Case)给一部电影评分。最初,他们的意见权重相等。
- 他们对一部电影进行评分,系统给你一个推荐。
- 你观看这部电影并给出自己的评分(反馈)。
- 系统将你的评分与评论家进行比较。如果你同意Bolu但不同意Aly,系统会增加Bolu意见的权重,并降低Aly的权重。
- 随着时间的推移,系统"学习"你特定的偏好。
生成式人工智能与大型语言模型 像ChatGPT这样的LLM并不具备人类意义上的"知识"。相反,它们根据海量的互联网数据计算下一个词应该是什么的统计概率。
- 偏见陷阱:由于LLM从互联网学习,它们继承了互联网的偏见。例如,谷歌研究发现,当LLM生成简历时:
- 对于男性,它们使用"竞争性强"、"自信"、"领导力"等词。
- 对于女性,它们使用"有爱心"、"关怀他人"、"团队导向"等词。
- 批判性思维:开发者必须保持批判性。仅仅因为人工智能产生答案,并不意味着它是正确或无偏见的。
效率与效能
- 效能:能够成功完成任务(例如,编写一个能运行的程序)。
- 效率:使用最少的资源完成任务(更少的代码、更少的内存、更少的时间)。
- 职业建议:首先,确保效能。然后,努力提升效率。
以下是第四部分,涵盖数据管理、大数据以及教师对技术社会影响的最终思考。
第四部分:数据、大数据与未来
数据与信息:冰箱练习 数据是原始事实的集合,但只有在被组织并赋予意义后,它才成为信息。
- 练习:如果我告诉你我有一个高170厘米、很重、有门、内部很冷的盒子,每个陈述都是一条数据。当你把它们结合起来时,你识别出了冰箱的模式。
- 启示:对计算机科学家来说,我们的工作是将数据块组织成能提供知识的序列。如果数据有偏见(例如,如果你只见过白色的冰箱),你的信息将是不完整的。
数据存储的演进 数据按层级组织:字符 → 字段 → 记录 → 表 → 数据库。为了连接这些表,我们使用关键字段(如学号),它是一个唯一标识符。
管理这些数据主要有两种方式:
- 面向文件的系统(旧式):每个部门都有自己的文件。这导致冗余(数据重复)和不一致性(在图书馆更新了地址,却忘了在财务处更新)。
- 数据库管理系统:一个集中的系统,每个部门都访问同一数据源。它是安全、结构化的,并避免不一致性。
大数据革命 "大数据"不仅仅是拥有大量数据;它是一种理念的转变。传统的SQL(关系型) 数据库是刚性和集中的。它们对银行和学校来说非常出色,因为它们安全,但它们不易"扩展"(难以快速增长)。
大数据的三个V:
- 体量:来自每笔交易和登录的海量数据。
- 速度:数据生成和处理必须达到的惊人速度。
- 多样性:数据不再只是数字;还包括图像、音乐和社交媒体帖子。
因此,我们现在使用NoSQL(非关系型) 数据库,如MongoDB或Cassandra。它们灵活且可以水平扩展。现代公司如亚马逊或TikTok使用混合方法:为了速度和可扩展性使用NoSQL,为其最重要的永久记录使用SQL。
社会影响与伦理 人工智能是一种超越机器人的工具;它存在于我们的搜索算法、翻译工具和医疗保健中。然而,我们必须记住:
- 人工智能缺乏人类内容:它无法感受情感或像人类老师或老板那样给予"第二次机会"。
- 就业岗位替代:虽然人工智能将取代许多任务,但它也打开了新的机会"窗口"。你必须学会驾驭和适应。
- 隐私与信任:我们24小时在线。作为开发者,你有能力保护或暴露人们的隐私。
最终结论:你作为开发者的角色 技术不是一次性发明;它是永不满足的人们驱动的演进。你们是这一演进的下一个世代。
教授的最后建议:
- 成为更好的使用者:理解你使用的工具。
- 成为负责任的开发者:知道你的算法可能伤害或帮助他人。
- 保持批判性:人工智能是一种工具,不能替代你的判断。不要丧失批判和验证机器给出结果的能力。
第一课的文字内容至此结束。
Insights on AI in Information Security / AI 在信息安全领域的启发
Based on the lecture "Big Data and AI: Revolutionary Developments," here are three critical insights into how these concepts transform Information Security.
1. The Paradigm Shift: From "Signature-Based" to "Anomaly Detection"
Source Concept: Deductive Reasoning (Rules) vs. Inductive Learning (Patterns) & Unsupervised Learning.
- English Reflection:Traditionally, antivirus software worked like the "Deductive Reasoning" mentioned in the lecture: it relied on specific, human-written rules (signatures) to identify known malware. If the code matched the rule, it was blocked.However, AI introduces Unsupervised Learning. Just as the lecture explained finding patterns in unlabeled data, AI in security can analyze network traffic to establish a "baseline of normality." It doesn't look for a known virus; it looks for behavior that deviates from the pattern (anomalies). This allows us to detect "Zero-Day Attacks" (unknown threats) that no human has written a rule for yet.
- 中文启发:从“特征匹配”到“异常检测”源概念:演绎推理(规则)与归纳学习(模式)以及无监督学习。传统的杀毒软件工作方式类似于课程中提到的“演绎推理”:它依赖于人类编写的具体规则(病毒特征库)来识别已知的恶意软件。如果代码符合规则,就会被拦截。然而,AI 引入了无监督学习。正如课程中解释的“在无标签数据中发现模式”,安全领域的 AI 可以分析网络流量以建立“正常行为基准”。它不再是寻找已知的病毒,而是寻找偏离常规模式的行为(异常)。这使我们能够检测到没有任何人类为其编写过规则的“零日攻击”(未知威胁)。
2. The "Autonomous Security Agent": Speed and Scale
Source Concept: The AI Agent Cycle (Perception → Reasoning → Action) & The 3Vs of Big Data (Velocity).
- English Reflection:The lecture defined an AI Agent as a system that perceives, reasons, and acts. In Information Security, the "Velocity" (speed) of attacks is now too fast for humans. A hacker can automate an attack to hit thousands of ports in seconds.Applying the Agent Cycle to security creates "Security Orchestration, Automation, and Response" (SOAR).
- Perception: Sensors ingest massive logs (Volume).
- Reasoning: The model decides if an activity is malicious based on weights and thresholds (Neural Networks).
- Action: The system automatically isolates the infected device or blocks the IP without waiting for a human admin. This matches the lecture's definition of efficiency: responding instantly to save resources.
- 中文启发:“自主安全智能体”:速度与规模源概念:AI 智能体循环(感知 → 推理 → 行动)以及大数据的 3V 特性(高速 Velocity)。课程将 AI 智能体定义为一个能够感知、推理和行动的系统。在信息安全中,攻击的“速度(Velocity)”现在太快了,人类无法跟上。黑客可以自动化攻击,在几秒钟内攻击数千个端口。将智能体循环应用于安全领域,就构成了“安全编排、自动化与响应”(SOAR):
- 感知:传感器摄入海量日志(体量)。
- 推理:模型根据权重和阈值(神经网络)判断活动是否恶意。
- 行动:系统自动隔离受感染设备或封锁 IP,而无需等待人类管理员。这符合课程中对“效率”的定义:即时响应以节省资源。
3. The "Adversarial AI": Ethics and The Double-Edged Sword
Source Concept: The Tool Metaphor (AI can help or harm) & Generative AI Bias.
- English Reflection:The lecture emphasized that AI is a tool that reflects the intent of its user. In security, this is the most dangerous insight. Just as we use LLMs to generate "effective" code or CVs, attackers are using Generative AI to write polymorphic malware (code that changes itself to hide) or to craft perfect phishing emails that lack the grammar mistakes of the past.Furthermore, the "Bias" mentioned in the lecture applies to security profiling. If an AI security model is trained on biased data, it might flag legitimate traffic from certain regions or user groups as "malicious" (False Positives), causing denial of service. Developing ethical, unbiased security AI is just as important as building powerful algorithms.
- 中文启发:“对抗性 AI”:伦理与双刃剑源概念:工具隐喻(AI 可善可恶)以及生成式 AI 的偏见。课程强调 AI 是一个反映使用者意图的工具。在安全领域,这是最危险的启示。正如我们使用大语言模型(LLM)来生成“高效”的代码或简历,攻击者也在使用生成式 AI 编写多态恶意软件(会自动变化以隐藏自己的代码),或制作完美的网络钓鱼邮件(不再有过去的语法错误)。此外,课程中提到的“偏见”也适用于安全画像。如果一个 AI 安全模型是在有偏见的数据上训练的,它可能会将来自特定地区或用户群体的合法流量错误地标记为“恶意”(误报),从而导致服务拒绝。开发符合伦理、无偏见的安全 AI,与构建强大的算法同样重要。
Comments 1 条评论
20260119 澳门大学
Big data and AI: revolutionary developments Miguel Gomes da Costa Junior